

"Fingerprints of the Thief": How a Glitch in Descript Drew Me Into the Disturbing World of OpenAI
"Fingerprints of the Thief": How a Glitch in Descript Drew Me Into the Disturbing World of OpenAI
Plus: Is Paradiso Media Stiffing Its Contract Workers?


Hello, Squeeze Nation!
If you’re new around here, welcome!
A few quick notes:
Great Pods Founder and Wearer of Scarves Imran Ahmed (pictured above) made the brave decision to let me take over the most recent edition of his newsletter and it was a joy to write. (Great Pods curates podcast criticism; it’s kind of like Rotten Tomatoes for fans of audio entertainment.) Click here to pull back the curtain on what I’ve been listening to lately, which TV recap podcasts I’m queueing up this week, and a selfie I took at a very exclusive event. (Subscribe to Imran’s newsletter here.)
I’m hearing rumblings that podcast shop Paradiso Media is withholding payments owed to a number of its contract workers. If you know anything about this, or if you have been impacted, please hit reply on this email.
For those not familiar with Descript, which is central to today’s story, it’s an app that allows podcasters and other creators to edit video and audio files in the same way they would edit a Word or Google doc; the first step in the process is transcribing users’ media files. The Descript app is used by more than six million creators, one of which, full disclosure, is me.
If you enjoy today’s issue of The Squeeze, please like, share, and have me on your podcast to talk about it. And as always, reach out to me with tips at skyepillsatwork@gmail.com; I’m also on Signal and WhatsApp.
Alright, let’s hit it!
We are aiding and abetting our own destruction.
— Jon Stewart, discussing generative AI on The Town with Matthew Belloni
"Fingerprints of the Thief": How a Glitch in Descript Opened My Eyes to the Dangers of OpenAI
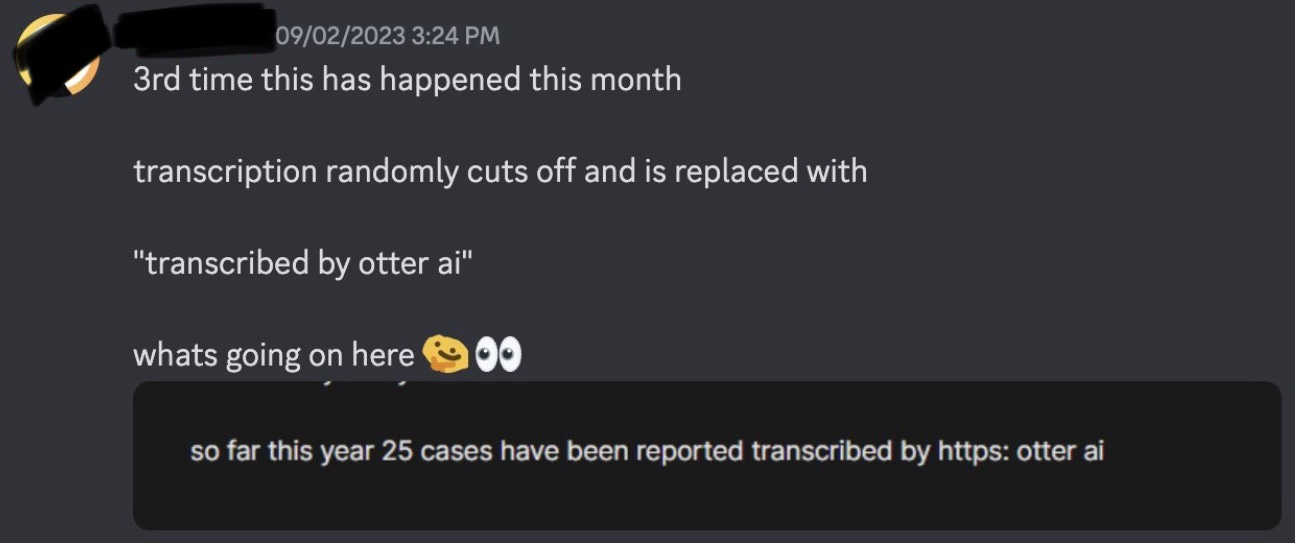
Late last year, a podcaster sent me a screenshot of a transcript produced by Descript, in which the phrase “Transcribed by https: otter. ai” had appeared. They wondered if Descript was (secretly? nefariously?) using Otter instead of its own technology, but a contact of mine who works at Otter insisted that that wasn’t the case.

My source’s experience wasn’t unique; multiple users were coming across the same thing.

Around this time, I connected with Descript’s VP of Marketing Whitney Steele, who explained that the company has always used third-party AI software to power transcriptions — a surprise to me and most of my podcaster friends, as we would have had to dig around in the company’s online “reference manual” to discover it — but she said, they hadn’t ever used Otter AI. Over the years, Descript had used Google AI, Rev AI, and since September of 2022, a transcription tool called Whisper, which had been developed by the company behind ChatGPT, OpenAI.
According to Steele, the glitches users were seeing were “AI hallucinations,” or put simply, nonsensical or incorrect information generated by an AI model. This phenomenon had a zeitgeisty moment a few weeks ago, when a search result generated by Google AI recommended that people eat “at least one small rock a day.” It turned out that the model had hallucinated the advice because of a satirical article published by The Onion, in which geologists made the same suggestion. When I spoke with Steele last March, she explained the Descript glitches to me in a similar way. “It’s impossible say why specific hallucinations happen,” she told me, but “they usually have to do with the data an AI model is trained on.”
It followed that Whisper must have trained on transcriptions and was accidentally “hallucinating” chunks of that data into someone else’s file. But if that were possible, could Whisper also hallucinate pieces of one person’s Descript transcript into another’s by mistake? Steele said there was “zero chance” because “Descript doesn’t use users’ content to train the transcription model” and the company “[doesn’t] share data with OpenAI or anyone else.” (Descript does use users’ project data to train some of their other AI models, but only with consent; and they can opt-out at any time.)
After mentioning this reporting to a few friends, one of them shared that they had witnessed glitches in their Descript transcripts, too — at least twice. The first time, the name of a different transcription service had appeared, but the second time, someone named Muneet had inserted himself mid-transcript to ask that we “hit that subscribe button to continue watching.”

This felt like something altogether different; instead of the relatively innocuous name of a transcription company, the actual words of a creator — probably a YouTuber? — had popped up into my friend’s work. What was going on here?
That was March; then came April, and a major story in the New York Times:

According to the paper’s reporting, in a “desperate” bid to obtain more “training data” — which is necessary to advance AI models — OpenAI and other tech companies had “ignored corporate policies, altered their own rules and discussed skirting copyright law.” As part of this effort
OpenAI researchers created a speech recognition tool called Whisper. It could transcribe the audio from YouTube videos, yielding new conversational text that would make an A.I. system smarter.
The OpenAI team behind the effort, which included the company’s president, knew that they were “wading into a legal gray area,” because
YouTube prohibits people from not only using its videos for “independent” applications, but also accessing its videos by “any automated means (such as robots, botnets or scrapers).”
But, according to sources for the Times’ story, the team convinced themselves that “training A.I. with the videos was ‘fair use,’” and scraped north of a million hours of content from the platform anyway.
Now Muneet’s appearance made a lot more sense: Whisper had probably scarfed down his YouTube show during its raid on the platform, and was now hiccuping up the evidence for others to see.
“Generative AI is just another way to describe wholesale theft of intellectual property,” Jussi Ketonen, a former computer scientist at the Stanford Artificial Intelligence Lab (who, full disclosure, is also my Dad) told me last weekend. “And AI hallucinations are like the fingerprints of the thief. It’s as if I broke into your house and stole your jewelry, and on my way out the door, I told you that I did it for the sake of humanity.”
Many organizations agree with this assessment and have taken legal action against OpenAI and other generative AI companies, including the New York Times, New York Daily News, Chicago Tribune, The Authors Guild of America, but lawsuits have also sprung up from independent digital workers. For example, a group of software developers filed a class action suit against OpenAI, Microsoft, and Github, that claims that the companies “violated the legal rights of a vast number of creators who posted code or other work under certain open-source licenses on GitHub.”
In any event, while “fair use” is litigated by our sluggish court system, it’s probably safe to assume that AI companies will continue their spree, and OpenAI will lead the way. As technology journalist Casey Newton said during a conversation about the company’s scraping of YouTube on Hard Fork a few weeks ago, “it’s a classic case of ask for forgiveness, not permission, and they're going to push this as far as it will go.”
It’s unsettling to think that creators on Descript are using software that was originally designed to gobble up the work of fellow creators, but what are their alternatives? They could switch to another app, but many competing transcription services have had their fair share of problems, too. Creators could lobby Descript to use different software, but that won’t happen. Why? First, despite its hallucination problem (and, I’m told, a few other pesky bugs), the software works pretty well for most users. And second, because of this:

About 18 months ago, Descript landed a $50 million round of funding led by the OpenAI Startup Fund, which is basically a container of money pooled from Microsoft and other OpenAI partners (according to SEC filings, the fund had raised more than $325 million, as of this past March). In a video introducing the launch of the fund in 2021, Sam Altman explained that while OpenAI would not be a direct investor in the fund, the company’s leadership would manage it. [Quick sidenote: earlier this year, Axios reported that Sam Altman actually owned the entire fund, a massive f**k-up, which a spokesperson probably made worse when they explained that “we wanted to get started quickly and the easiest way … was to put it in Sam's name.” The fund removed control from Altman six weeks later. Ask for forgiveness, not permission!]
Up until this reporting, I was unaware of the connection between these companies, and that’s probably because the funding announcement dropped a few weeks before ChatGPT became a worldwide phenomenon, and many months before the number of troubling headlines about OpenAI would pile so high that articles compiling them would become a thing. Even if I did come across a headline about the funding back then, I obviously didn’t make much of it.
But seeing the news now, after so many of us have been unwittingly dragged into an “AI race” between powerful players who seem utterly uninterested in the impact of their decisions on creators, it feels ominous. Descript is a company with access to the exact thing that OpenAI is desperate for and has, in the past, taken potentially illegal action to obtain. What’s to stop the company from pressuring Descript to share their data “for the sake of humanity?”
I don’t think it’s unreasonable to imagine this scenario. Having worked with many VC-funded startups — and also, just by having a brain — I know that pleasing your investors is high on the list of a startup’s priorities. When Descript ditched RevAI for for OpenAI’s Whisper product less than a month before their funding was announced, it’s a good bet that they were making this calculation. The dynamic between startups and investors is complicated. (When I asked checked back in with Descript, Steele told me that when their team chooses a third-party AI model for transcription “the driving factor is accuracy.”)
Another possibility is that OpenAI could acquire Descript to get access to its data. This is not a product of my wild imagination; the Times’ examination found that back in 2021, in addition to scraping YouTube, the OpenAI team had “considered buying startups that had collected large amounts of digital data.” The OpenAI Startup Fund launched late that same year, and Descript was its second investment. (Interestingly, ten months later, Descript acquired Squadcast, which also houses a boatload of content.) Is it possible that OpenAI’s decision to invest in Descript was the first step within a larger plan?
Steele told me that she hasn’t seen anything from OpenAI that would lead her to worry about these scenarios and I believe her. But I have a harder time accepting that OpenAI — which is being sued by numerous people and entities for copyright infringement (all separate links!); appears to have deliberately hired ScarJo’s vocal twin to voice ChatGPT after the actor declined the job; has lost or fired many high-profile staffers including its chief scientist and members of a now-disbanded risk and safety team; regularly bends the truth, outright lied for over a year about who had financial control over a multimillion dollar fund, is the subject of an FTC investigation, engaged in the (possibly illegal and definitely unethical) scraping of over a million hours of creator-generated YouTube data as well as other stuff — is a company that deserves our trust.
Time will reveal all.
Until then, keep your eyes on the jewelry, kids!
That’s it for me today; thanks for reading. If you enjoyed today’s story, please like, share, and have me on your podcast to talk about it. If you have tips, reach me at skyepillsatwork@gmail.com; I’m also on Signal and WhatsApp.
Take care of each other out there,
Skye
Postscript:
A statement from the developers who filed a class action suit against OpenAI, Microsoft and GitHub:

Wow, Skye! What an incredible article. I was spellbound. I would just like to share my own quick experience with Otter.ai transcription which I was in love with to transcribe my podcasts and videos until they doubled their fees during the pandemic which forced me to find another service and Whisper came along and was completely free which was one way for them to access more data for scraping. You have brilliantly pieced all the players together. I'm looking forward to more on this.
It's GPT, not GBT, but regardless - as a new Descript paid user this is highly concerning. I understand the need for more training data, but there has to be a better model for obtaining it moving forward. People don't want their work to be stolen, and with good reason, and none of this constitutes fair use under any definition of the term. Thanks for reporting on this!